类案检索 与 对比报告生成 系统
Case Retrieval
and
Comparative Report Generation System
2025 · Undergraduate Graduation Project
FastAPI · React · FAISS · DashScope · DeepSeek
github.com/belfiore04/similar_case_search
WHY?
律师在准备案件、梳理辩护思路时,需要做大量类案检索。
现有工具——无讼、北大法宝、Alpha
核心是关键词检索:
律师必须先知道"我要搜什么"才能搜。
但很多时候,律师自己也说不清,"相似"是哪几个维度的相似。
What?
类案检索让律师直接用一段自然语言案情
系统通过结构化抽取 + 多路切分检索 + 引用追溯
替律师找出事实模式、法律关系、争议焦点都接近的过往判例
返回一份带引用的对比分析报告
A note on RAG
做这个项目我想清楚的一件事是:RAG 不是"加个向量库就行"
真正决定 RAG 好不好用的,
是结构化前置、引用追溯、和 Prompt 工程
向量检索本身,反而是最容易被替代的一环。
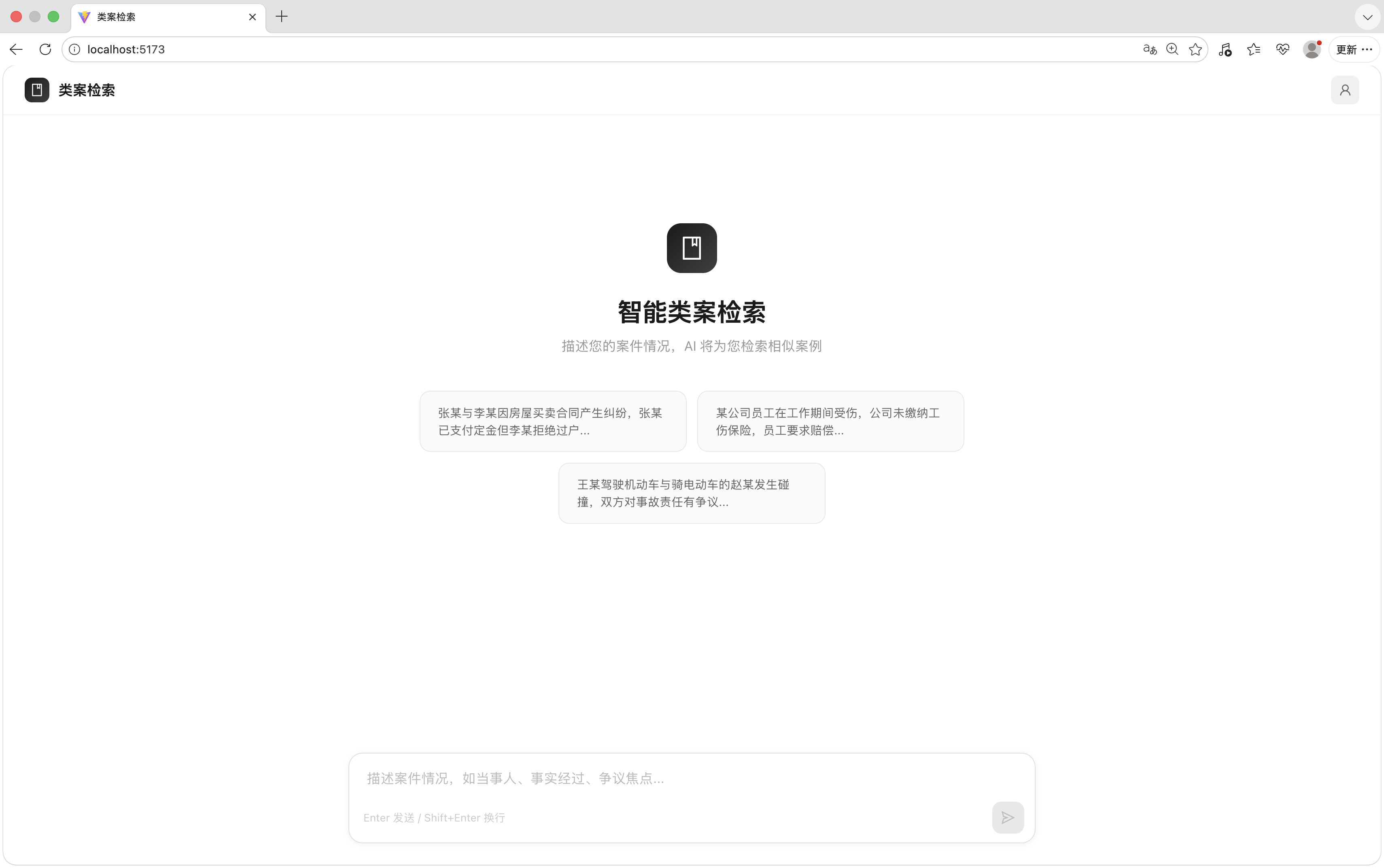
查询页
传统法律检索工具要求律师先想好关键词
但很多时候律师自己也说不清"相似"是哪几个维度。
我把入口设计成纯自然语言输入
把案情扔进去就好
系统去理解、拆解、检索。
降低门槛的同时,反而提升了检索精度。
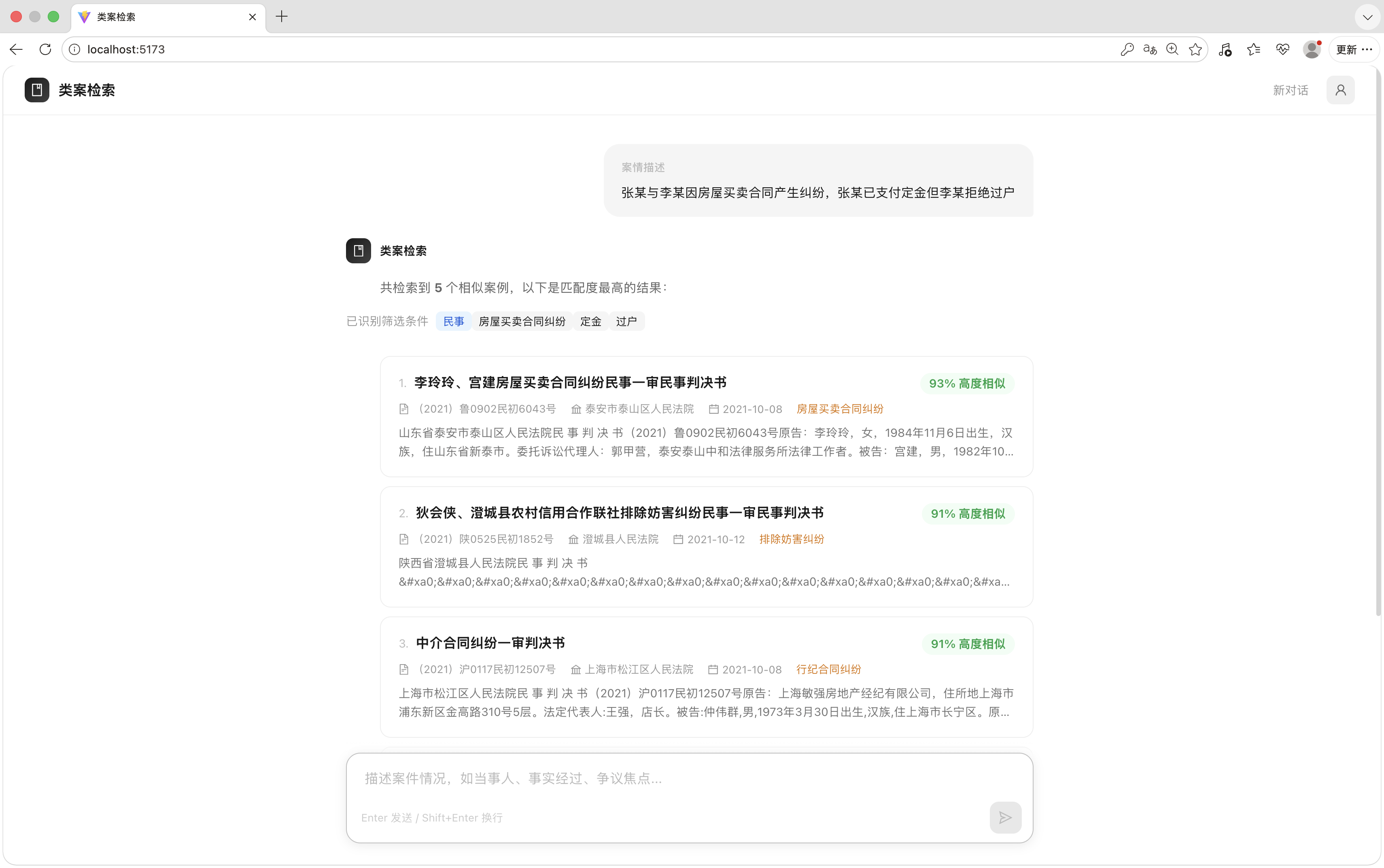
查询结果
每个候选案例除了案名和相似度
还展示了关键事实与争议焦点
帮律师不打开详情就能快速判断哪些值得深看
这里我主动做了取舍:不展示完整判决摘要
因为在专业工具里
信息过载比信息不足更影响判断

报告生成页
这是用户最关心的一屏
报告我没用大段叙述
而是结构化的事实表格做对比
同一行可以横向扫"原案 vs 候选案"
在某个事实点上的异同
这是个有意识的取舍:
把 AI 的"创作自由"换成"对比的可读性"
在专业场景下,这是更稳的产品形态

相关法律条文
类案检索本身只走了一半
律师拿到"类似案件"之后
真正需要的是
"这些案件具体引用了哪些法条、怎么应用的"
所以我把法条应用从对比报告里独立出来
律师可以反向以法条为锚
看哪些类案在用同一个法条
这是写诉状时最需要的检索维度
而不是停在"找到类似案件"这个 70 分的位置
A note on 做减法
项目里我主动砍掉的东西很多
不展示完整判决摘要
不做大段报告叙述
不做端到端起诉书生成
砍掉它们的不是因为做不到
是因为做了之后产品反而更弱
专业场景下
信息过载比信息不足更影响判断
做减法的勇气比堆
功能难得多
A note on AI
一开始我想做"端到端帮律师写诉状"
跟法学生朋友聊过之后才发现
他们要的不是一个替自己写诉状的 AI
要的是"少花两小时翻判决书"
在专业、高风险的场景里
AI 的位置是 augmentation
不是 automation
这条判断
决定了我后面所有的产品取舍
专业产品的标准
不是"AI 能做什么"
是"用户能不能信任 AI 做的"
所以我用 "创作自由" 换 "可验证性"
用 "端到端自动化" 换 "augmentation"
用 "信息丰富" 换 "信息克制"
用户到底需要什么?
用户到底到底需要什么?
用户到底到底到底需要什么?